TL;DR
We discover that distilling a large model to a small one, then progressively re-adding teacher layers, creates a family of intermediate-sized models—all without any additional training. This 'boomerang' approach dramatically reduces the cost of deploying LLMs across diverse memory constraints.
Abstract
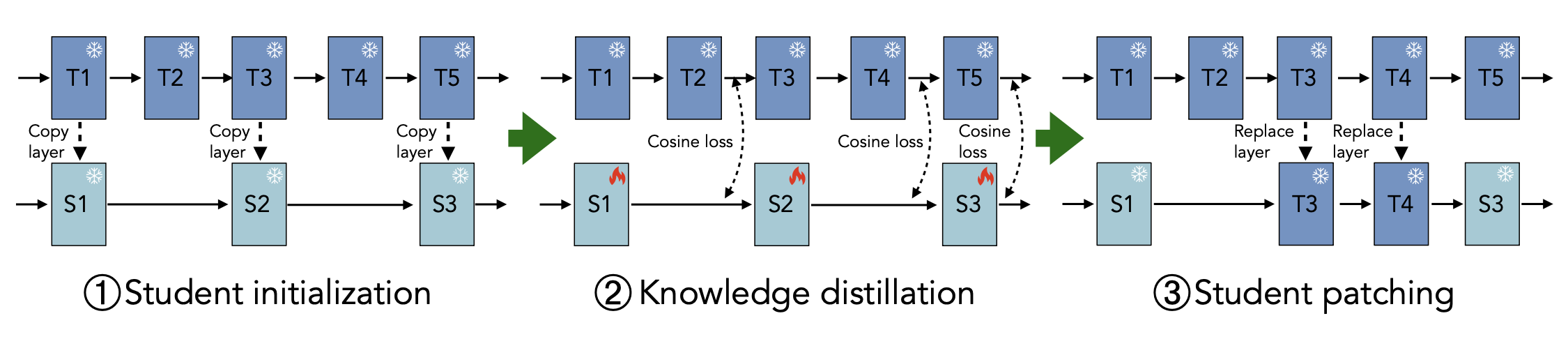
Large language models (LLMs) are typically deployed under diverse memory and compute constraints. Existing approaches build model families by training each size independently, which is prohibitively expensive and provides only coarse-grained size options. In this work, we identify a novel phenomenon that we call boomerang distillation: starting from a large base model (the teacher), one first distills down to a small student and then progressively reconstructs intermediate-sized models by re-incorporating blocks of teacher layers into the student without any additional training. This process produces zero-shot interpolated models of many intermediate sizes whose performance scales smoothly between the student and teacher, often matching or surpassing pretrained or distilled models of the same size. We further analyze when this type of interpolation succeeds, showing that alignment between teacher and student through pruning and distillation is essential. Boomerang distillation thus provides a simple and efficient way to generate fine-grained model families, dramatically reducing training cost while enabling flexible adaptation across deployment environments.
Citation
@inproceedings{kangaslahti2026boomerang,
title={Boomerang Distillation Enables Zero-Shot Model Size Interpolation},
author={Kangaslahti, Sara and Nayak, Nihal V. and Geuter, Jonathan and Fumero, Marco and Locatello, Francesco and Alvarez-Melis, David},
booktitle={International Conference on Learning Representations},
year={2026}
}