TL;DR
Want reward-guided decoding without the cost? GSI combines speculative inference with soft best-of-n, using a small model to propose candidates while provably approximating the optimal reward-tilted policy. Faster and often better than baselines.
Abstract
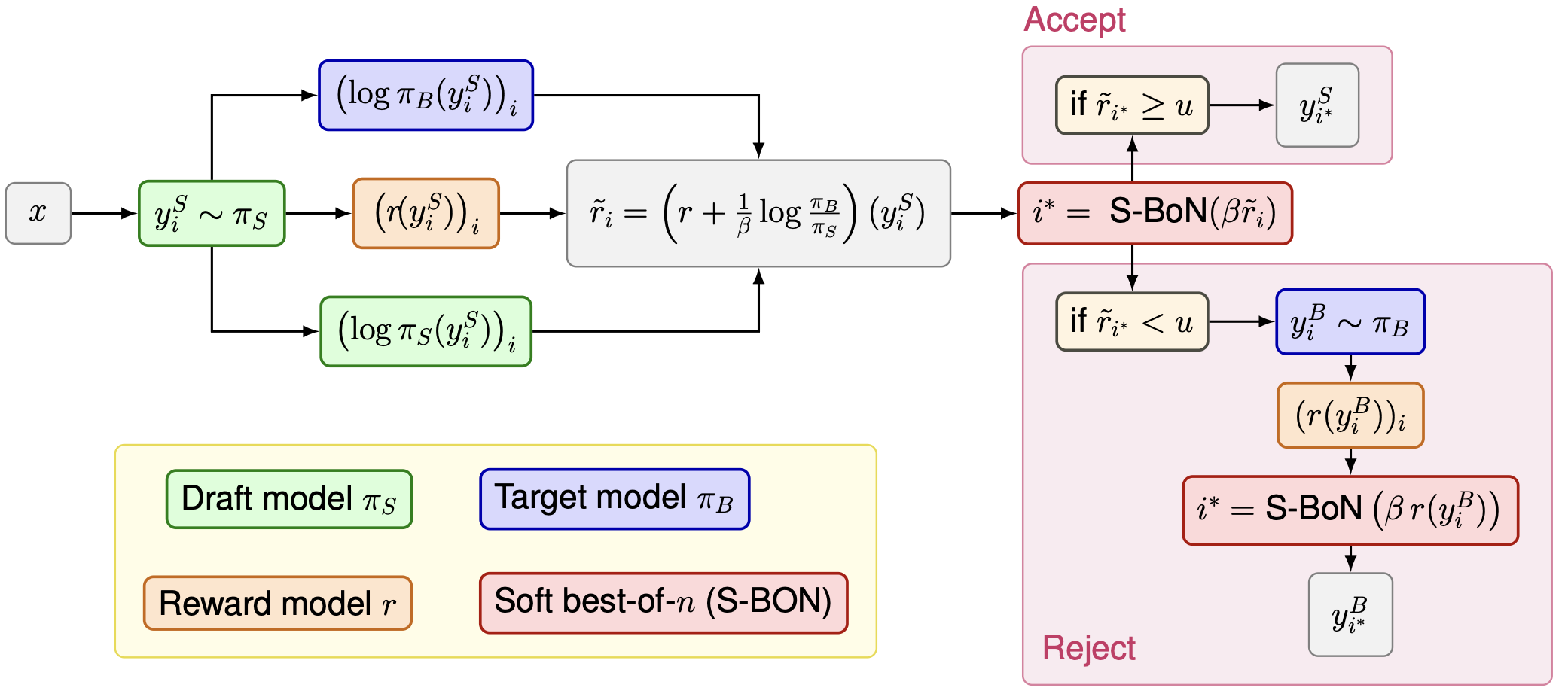
We propose Guided Speculative Inference (GSI), a novel algorithm for efficient reward-guided decoding in large language models. GSI combines soft best-of-n test-time scaling with a reward model r(x,y) and speculative samples from a small auxiliary model. We provably approximate both the optimal tilted policy of soft best-of-n under the base model, as well as the expected reward under the optimal policy. In experiments on reasoning benchmarks (MATH500, OlympiadBench, Minerva Math, MMLU-STEM, GSM8K), our method achieves higher accuracy than standard soft best-of-n and reward-guided speculative decoding, and in certain settings even outperforms soft best-of-n with the base model.
Citation
@inproceedings{geuter2026gsi,
title={Guided Speculative Inference for Efficient Test-Time Alignment of LLMs},
author={Geuter, Jonathan and Mroueh, Youssef and Alvarez-Melis, David},
booktitle={International Conference on Learning Representations},
year={2026}
}