TL;DR
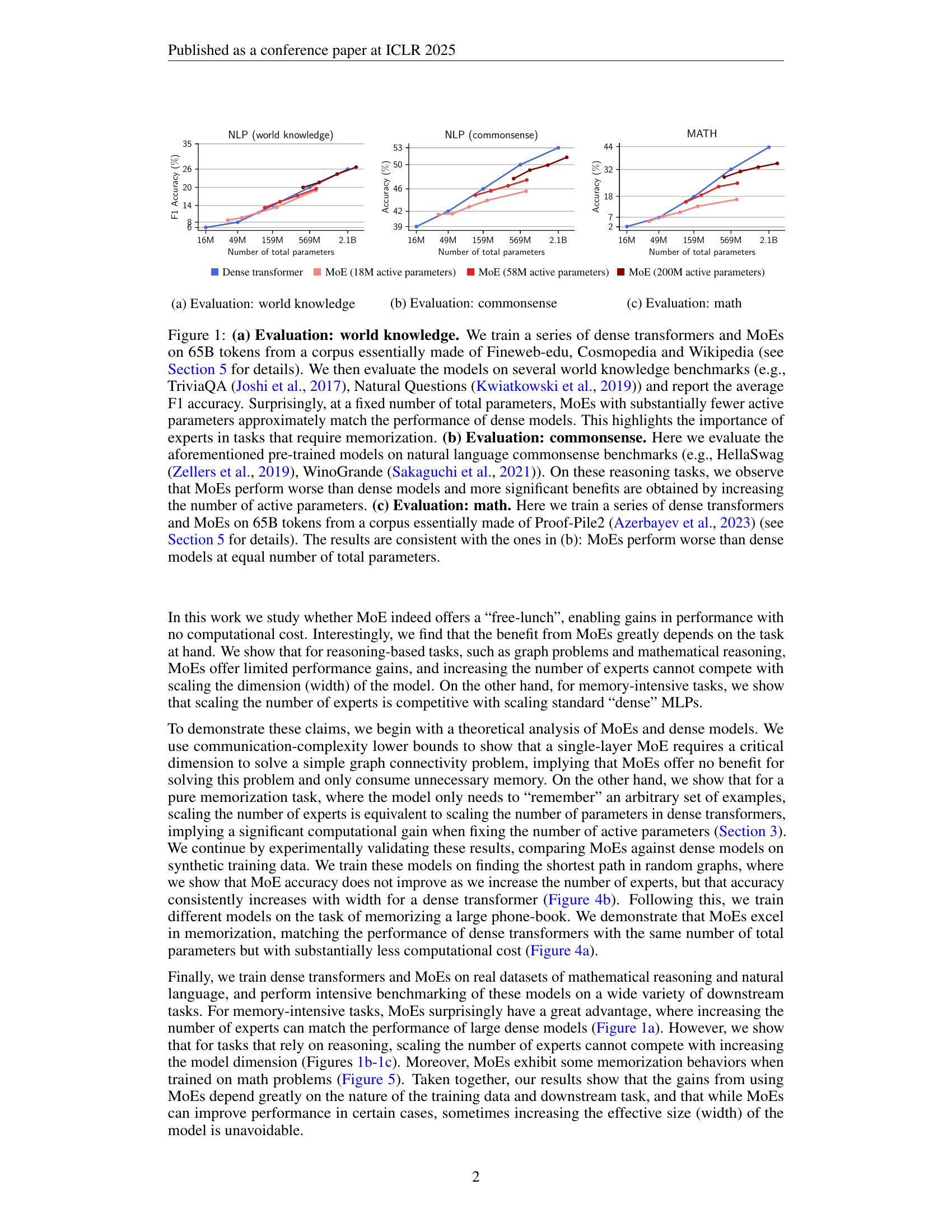
More experts help MoEs memorize better, but reasoning hits a ceiling. We prove theoretically and show empirically that some problems require dense networks—experts can't substitute for width when reasoning is needed.
Abstract
The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data.
Citation
@inproceedings{jelassi2025mixture,
title={Mixture of Parrots: Experts improve memorization more than reasoning},
author={Jelassi, Samy and Mohri, Clara and Brandfonbrener, David and Gu, Alex and Vyas, Nikhil and Anand, Nikhil and Alvarez-Melis, David and Li, Yuanzhi and Kakade, Sham M and Malach, Eran},
booktitle={International Conference on Learning Representations},
year={2025}
}