TL;DR
Long-context LLMs can consume far more text than they can reliably use, and inference-time thinking tokens don't help. We show that a small amount of context-specific test-time training beats current scaling strategies for long-context tasks.
Abstract
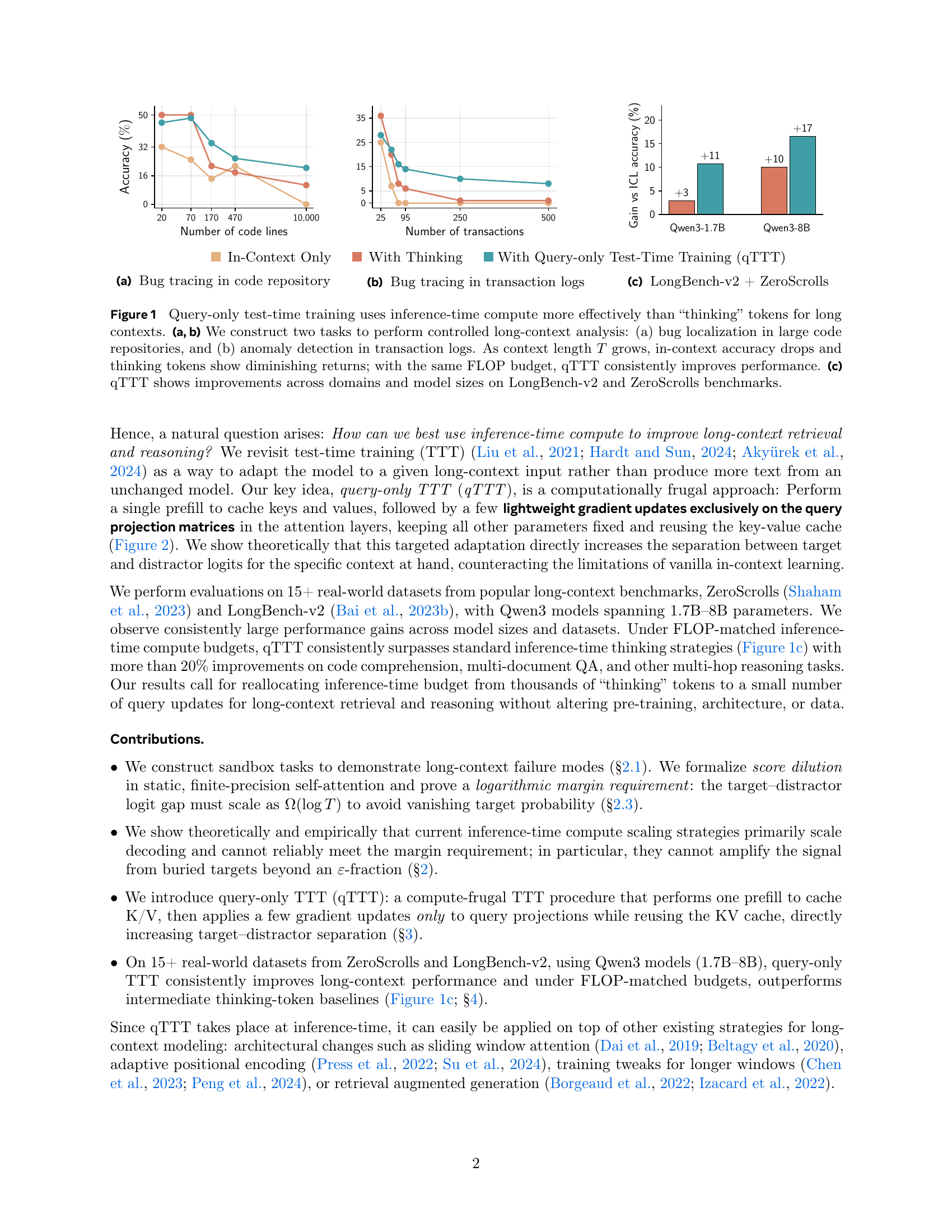
Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention.
Citation
@inproceedings{bansal2026ttt,
title={Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs},
author={Bansal, Rachit and Zhang, Aston and Tiwari, Rishabh and Madaan, Lovish and Duvvuri, Sai Surya and Khatri, Devvrit and Brandfonbrener, David and Alvarez-Melis, David and Bhargava, Prajjwal and Kale, Mihir Sanjay and Jelassi, Samy},
booktitle={International Conference on Learning Representations},
year={2026}
}